MetalLB on Hetzner Dedicated with vSwitch
When running Kubernetes on Hetzner Dedicated, there is no cloud load balancer. But you can provide public LoadBalancer IPs by attaching a routed IP range to a vSwitch and letting MetalLB announce addresses over L2.
Our setup:
- Calico (VXLAN + WireGuard)
- kube-proxy IPVS with strictARP
- ingress-nginx for ingress traffic
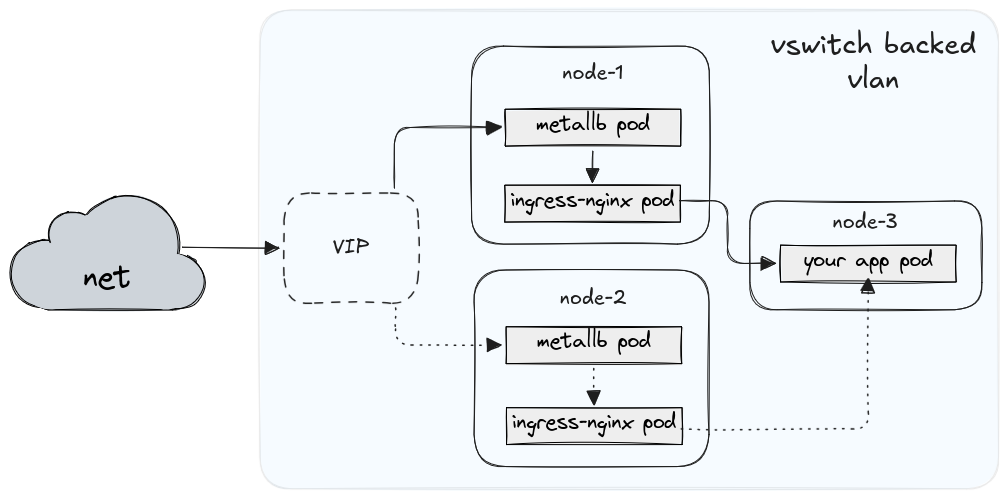
The diagram below illustrates the traffic flow: MetalLB advertises a public VIP from one node at a time, ingress-nginx receives it, and traffic is forwarded to the application pod running anywhere in the cluster.
1. Assign a public subnet to your vSwitch
Example routed block Hetzner provides:
Subnet: 123.45.67.32/29
Gateway: 123.45.67.33
Usable: 123.45.67.34–38
Broadcast: 123.45.67.39
Attach your dedicated servers to the vSwitch (VLAN ID e.g. 4000).
2. Configure vSwitch VLAN on each node
Each node gets a /32 from the subnet – Hetzner routes the whole /29 to your server.
Important note on routing table IDs
This guide uses routing table 200 as an example.
If you are running Cilium, avoid table
200: Cilium currently flushes all routes in table 200 on startup, which breaks vSwitch routing.For Cilium-based installations, any other unused routing table ID works (for example
201,300, or1001).
Create /etc/netplan/10-vlan-4000.yaml:
network:
version: 2
renderer: networkd
vlans:
vlan4000:
id: 4000
link: eno1
mtu: 1400
addresses:
- 123.45.67.38/32 # node-specific
routes:
- to: 0.0.0.0/0
via: 123.45.67.33
on-link: true
table: 200 # example table ID
- to: 123.45.67.32/29
scope: link
table: 200
routing-policy:
- from: 123.45.67.32/29
table: 200
priority: 10
- to: 123.45.67.32/29
table: 200
priority: 10
- from: 123.45.67.32/29
to: 10.233.0.0/18
table: 254
priority: 0
- from: 123.45.67.32/29
to: 10.233.64.0/18
table: 254
priority: 0
Apply:
netplan apply
3. Required sysctl settings
Create /etc/sysctl.d/999-metallb.conf:
net.ipv4.conf.all.arp_ignore=1
net.ipv4.conf.all.arp_announce=2
net.ipv4.conf.all.rp_filter=0
net.ipv4.conf.default.rp_filter=0
Why:
| Setting | Purpose |
|---|---|
arp_ignore=1 | Only reply to ARP queries for an IP on the correct interface – prevents conflicting replies from Calico/VXLAN. |
arp_announce=2 | Send ARP only from the interface that owns the VIP, required when MetalLB moves VIPs between nodes. |
rp_filter=0 | Disable strict reverse-path filtering – otherwise nodes drop return traffic sourced from VIPs or remote pods. |
4. kube-proxy + Calico adjustments
Enable strictARP in kube-proxy (IPVS mode):
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
ipvs:
strictARP: true
MTU must account for VXLAN + vSwitch + WireGuard overhead:
Calico MTU: 1280 (consistent across nodes)
5. Deploy MetalLB
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: vswitch
namespace: metallb-system
spec:
addresses:
- 123.45.67.34-123.45.67.36 # free VIPs
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: l2
namespace: metallb-system
spec:
ipAddressPools: ["vswitch"]
interfaces: ["vlan4000"]
Restart MetalLB speakers to pick up interface binding.
6. Ingress service configuration
For ingress-nginx:
spec:
externalTrafficPolicy: Local
Pro:
- Preserves client IP
- Prevents traffic hairpin across nodes
Tradeoff:
- Only one node handles a given connection (acceptable for ingress)
7. Verification
Confirm that your ingress-nginx Service received a public VIP:
kubectl get svc -n ingress-nginx ingress-nginx-controller
Expected example:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.233.53.156 123.45.67.35 80:30440/TCP,443:30477/TCP 17d
Inspect the Service events to see which node currently advertises the VIP:
kubectl describe svc -n ingress-nginx ingress-nginx-controller
Look for:
Events:
Normal nodeAssigned ... metallb-speaker announcing from node "control-plane-1" with protocol "layer2"
Then verify reachability from outside:
curl -I http://123.45.67.35
Failover test
- Identify the active announcer from the above events
- Shut that node down abruptly:
sudo poweroff
- Re-run:
curl -I http://123.45.67.35
Expected: traffic continues within ~1–2 seconds as another node picks up the VIP.
➡️ Note: VIPs do not appear in ip addr on nodes; they are held in IPVS and advertised via ARP. That is normal.
Acknowledgment
Thanks to Oleksandr Vorona (DevOps at Dysnix) for reporting a Cilium routing table conflict and helping improve this guide.
Wrapping up
This gives:
- Public LoadBalancer IPs
- Fast failover (~1-2s)
- Clean separation: pod networking via VXLAN/WireGuard, external via vSwitch
Alternatives:
- Hetzner Cloud Load Balancer (simpler, works with Dedicated too)
- Cilium with L2 announcements
We run hosting infrastructure, so controlling ingress networking ourselves matters (mostly to prove the point really). Hetzner still runs the vSwitch underneath, but it's more independent than relying on the cloud LB.
And if you'd rather not handle any of this yourself – Hostim.dev is now live. You can deploy your Docker or Compose apps with built-in databases, volumes, HTTPS, and logs – all in one place, ready in minutes.